|
Hi, I am Vihang Patil an Applied Scientist at Amazon. I work in the team RUFUS (chatbot for shopping).
Email / CV / Google Scholar / Twitter / Github |

|
|

|
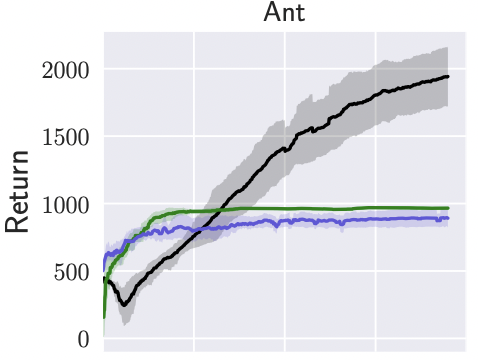
Thomas Schmied, Thomas Adler, Vihang Patil, Maximillian Beck, Korbinian Pöppel, Johannes Brandstetter, Gunter Klambauer, Razvan Pascanu, Sepp Hochreiter International Conference on Machine Learning (ICML), 2025 We propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed. |
|
|
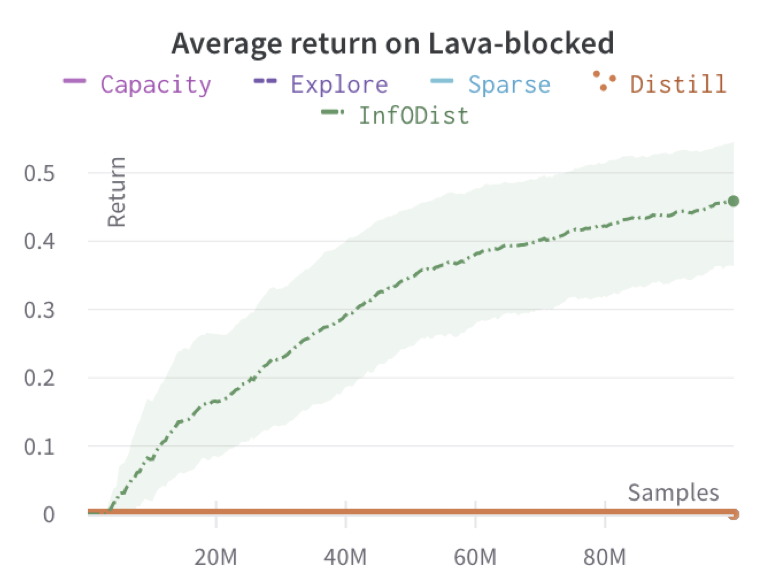
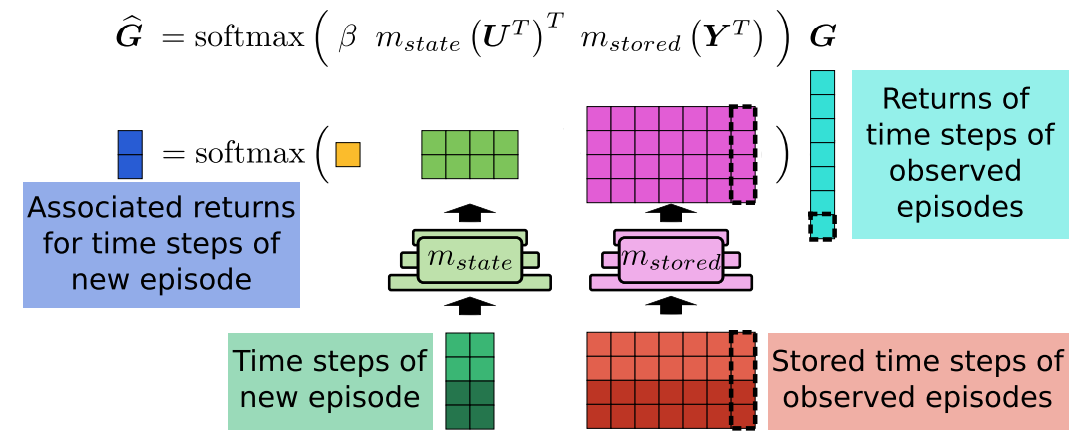
Thomas Schmied, Fabian Paischer, Vihang Patil, Markus Hofmarcher, Razvan Pascanu, Sepp Hochreiter Under Review We introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. |
|
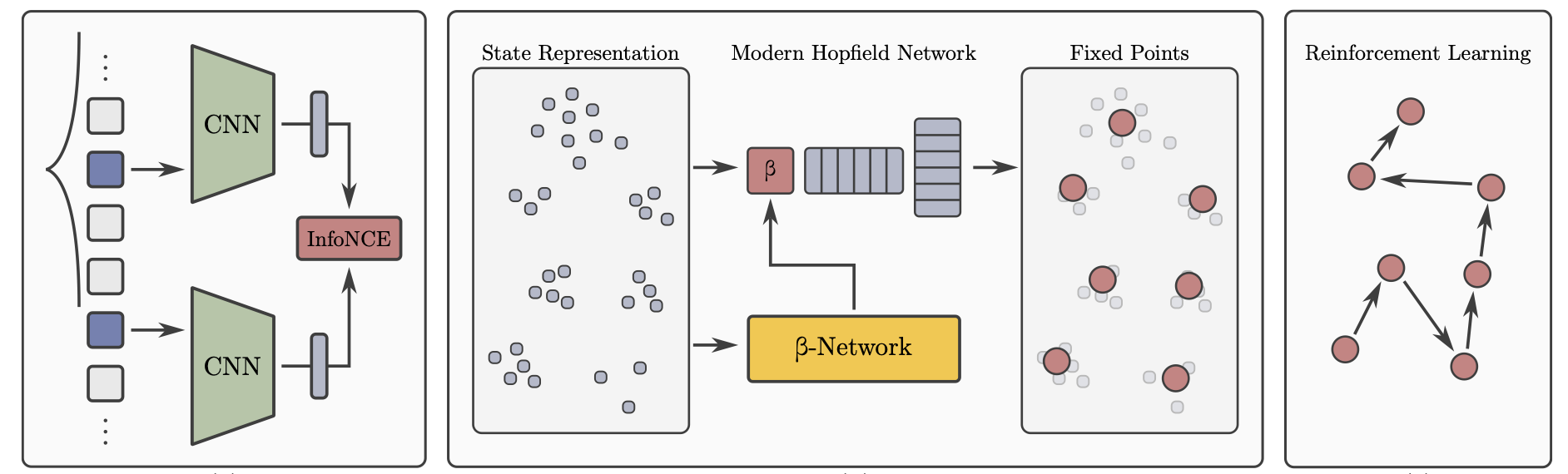
Vihang Patil, Markus Hofmarcher, Elisabeth Rumetshofer, Sepp Hochreiter Generalisation in Planning workshop @ Neurips, 2023 We propose contrastive abstraction learning to find abstract states, where we assume that successive states in a trajectory belong to the same abstract state. Such abstract states may be basic locations, achieved subgoals, inventory, or health conditions. Contrastive abstraction learning first constructs clusters of state representations by contrastive learning and then applies modern Hopfield networks to determine the abstract states. |
|
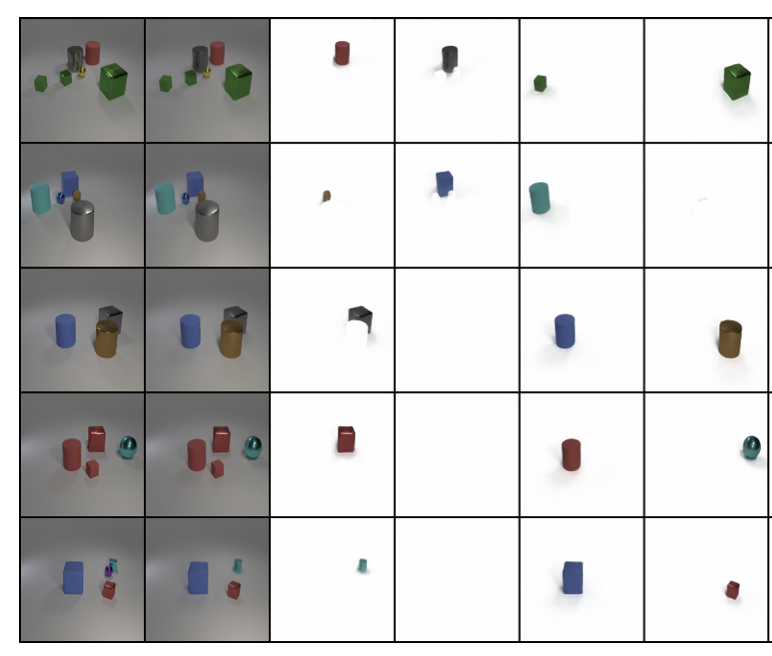
Vihang Patil, Andreas Radler, Daniel Klotz, Sepp Hochreiter COLLAS, 2024 We propose a non-iterative object-centric learning method using common building blocks, namely CNN, MaxPool and a modified Cross-Attention layer. A vastly modified version of this work is under review at Collas. |

|
Vittorio Caggiano, Guillaume Durandau, Huwawei Wang, Alberto Chiappa, Alexander Mathis, Pablo Tano, Nisheet Patel, Alexandre Pouget, Pierre Schumacher, Georg Martius, Daniel Haeufle, Yiran Geng, Boshi An, Yifan Zhong, Jiaming Ji, Yuanpei Chen, Hao Dong, Yaodong Yang, Rahul Siripurapu, Luis Eduardo Ferro Diez, Michael Kopp, Vihang Patil, Sepp Hochreiter, Rahul Siripurapu, Vihang Patil, Sepp Hochreiter, Yuval Tassa, Josh Merel, Randy Schultheis, Seungmoon Song, Massimo Sartori, Vikash Kumar Neural Information Processing Systems (NeurIPS), 2022 In the MyoChallenge at the NeurIPS 2022 competition track, the task was to develop controllers for a realistic hand to solve a series of dexterous manipulation tasks. This work paper the challenge and its solutions. Our method was a co-winner of the Baoding Balls task. |
|
Rahul Siripurapu, Vihang Patil,Kajetan Schweighofer, Marius-Constantin Dinu, Thomas Schmied, Luis Eduardo Ferro Diez, Markus Holzleitner, Hamid Eghbal-zadeh, Michael K Kopp, Sepp Hochreiter Deep Reinforcement Learning Workshop, Neurips, 2022 openreview A method to improve generalization in curriculum learning and an analysis of various factors affecting generalization. |

|
Vihang Patil, Markus Hofmarcher, Marius-Constantin Dinu, Matthias Dorfer, Patrick M. Blies, Johannes Brandstetter, Jose A. Arjona-Medina, Sepp Hochreiter International Conference on Machine Learning (ICML), 2022 blog / arXiv / video / code We present Align-RUDDER an algorithm which learns from as few as two demonstrations. It does this by aligning demonstrations and speeds up learning by reducing the delay in reward. (Long presentation at ICML, < 2%) |
|
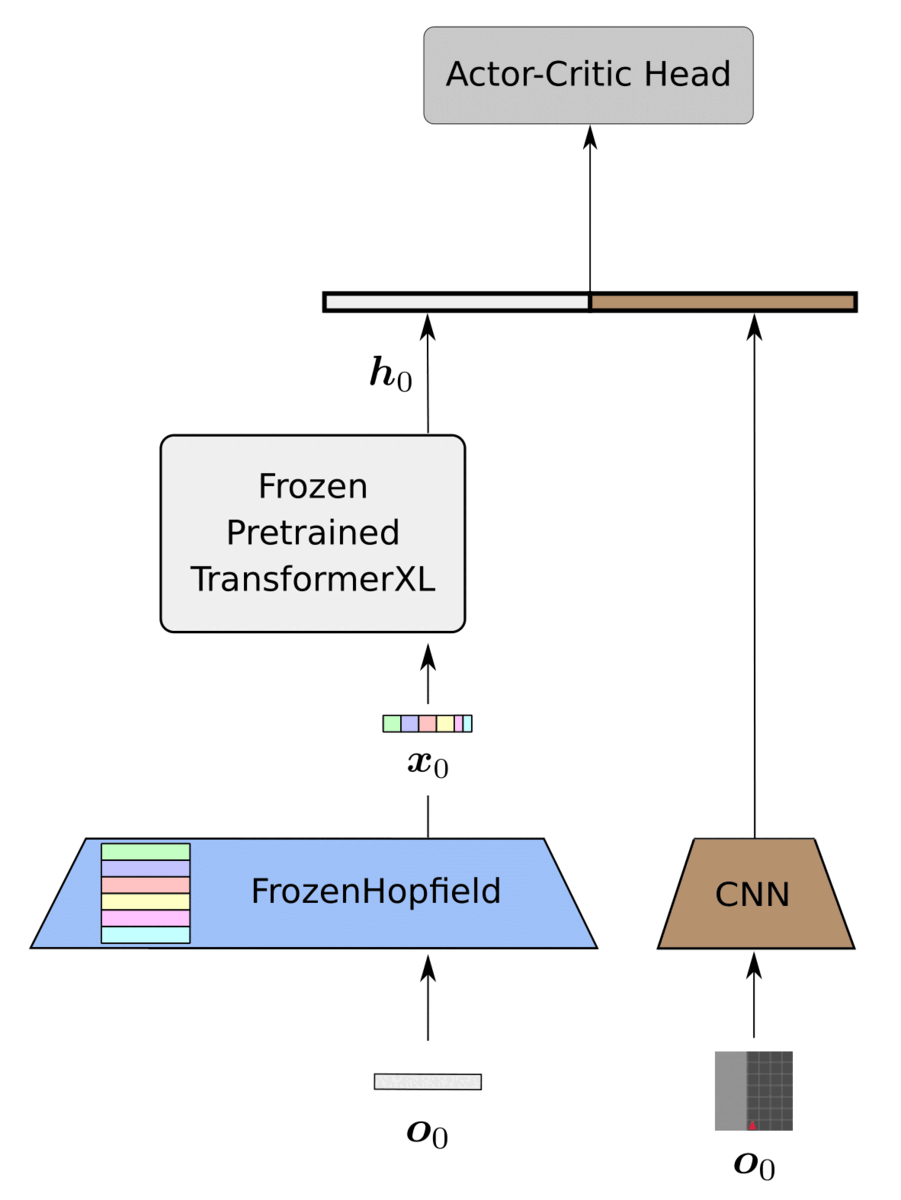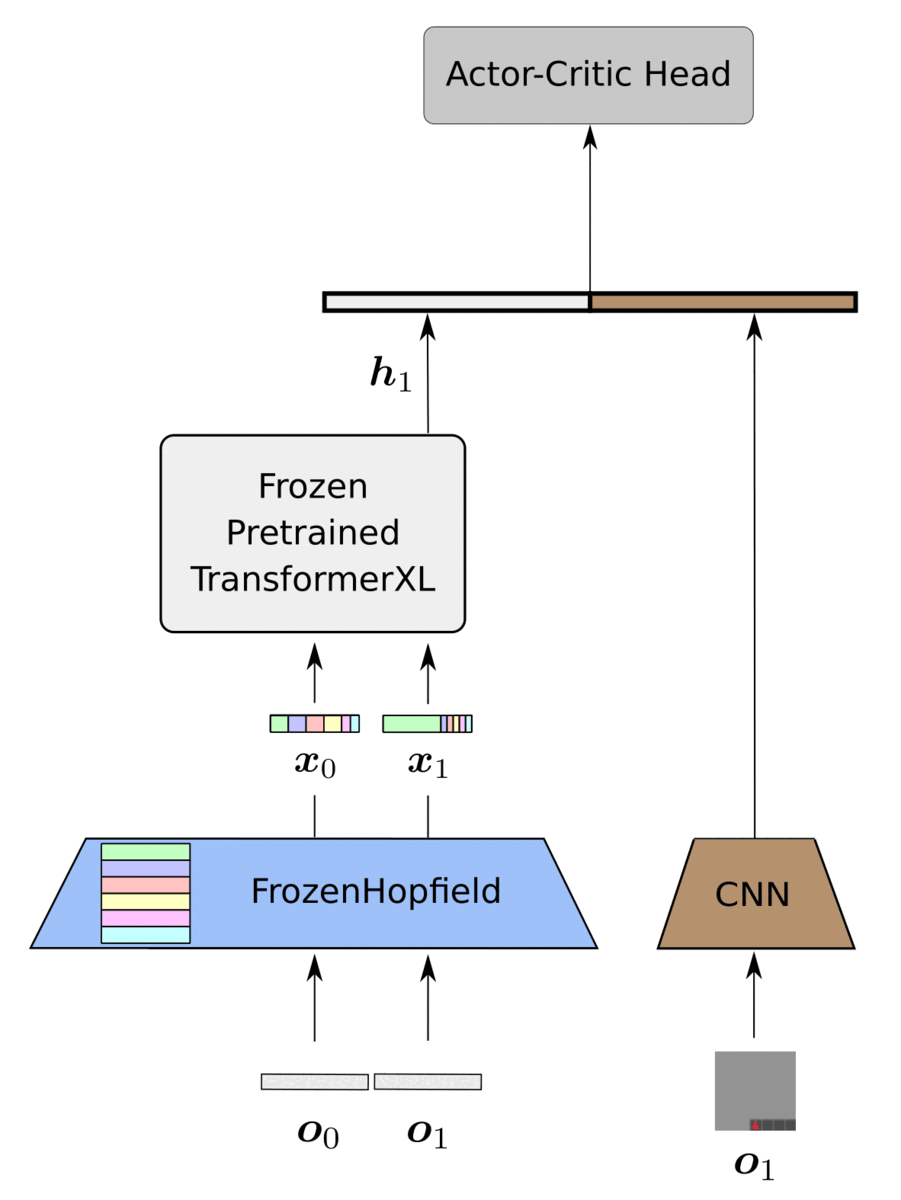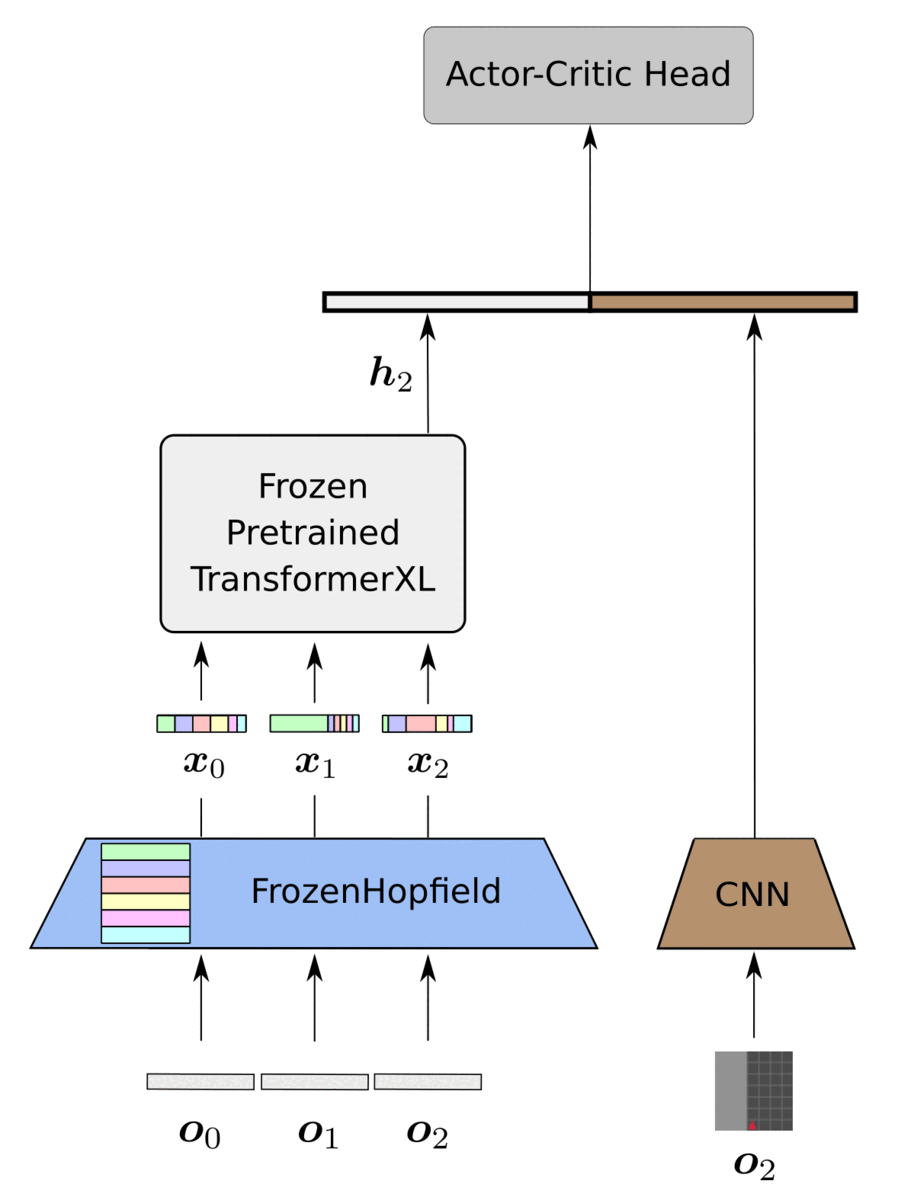
Fabian Paischer, Thomas Adler, Vihang Patil, Markus Holzleitner, Angela Bitto-Nemling, Sebastian Lehner, Hamid Eghbal-Zadeh, Sepp Hochreiter International Conference on Machine Learning (ICML), 2022 blog / arXiv / code HELM (History comprEssion via Language Models) is a novel framework for Reinforcement Learning (RL) in partially observable environments. Language is inherently well suited for abstraction and passing on experiences from one human to another. Therefore, we leverage a frozen pretrained language Transformer (PLT) to create abstract history representations for RL. (Spotlight presentation at ICML) |
|
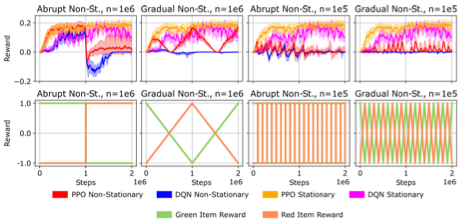
Christian Steinparz, Thomas Schmied, Fabian Paischer, Marius-Constantin Dinu, Vihang Patil, Angela Bitto-Nemling, Hamid Eghbal-Zadeh, Sepp Hochreiter Conference on Lifelong Learning (COLLAS), 2022 arXiv / code We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. |
|
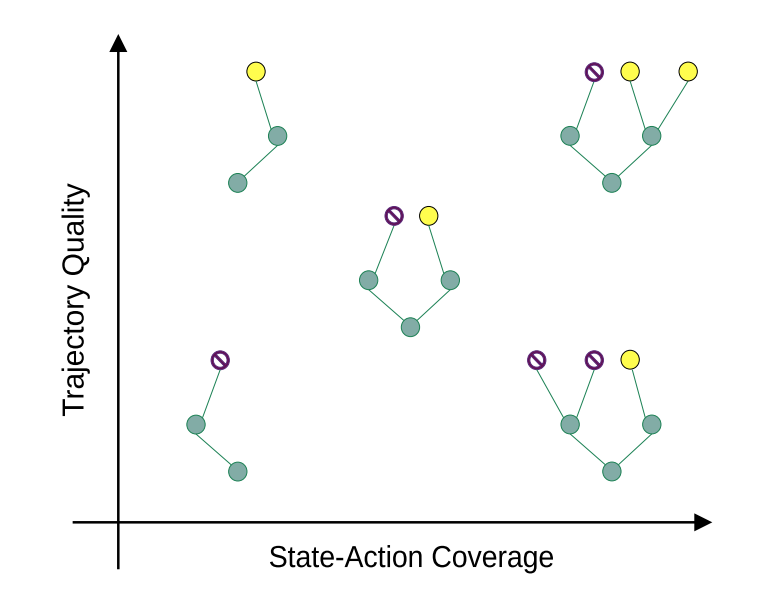
Kajetan Schweighofer, Andreas Radler, Marius-Constantin Dinu, Markus Hofmarcher, Vihang Patil, Angela Bitto-Nemling, Hamid Eghbal-Zadeh, Sepp Hochreiter Conference on Lifelong Learning (COLLAS), 2022 arxiv / code We conducted a comprehensive empirical analysis of how dataset characteristics effect the performance of Offline RL algorithms for discrete action environments. |
|
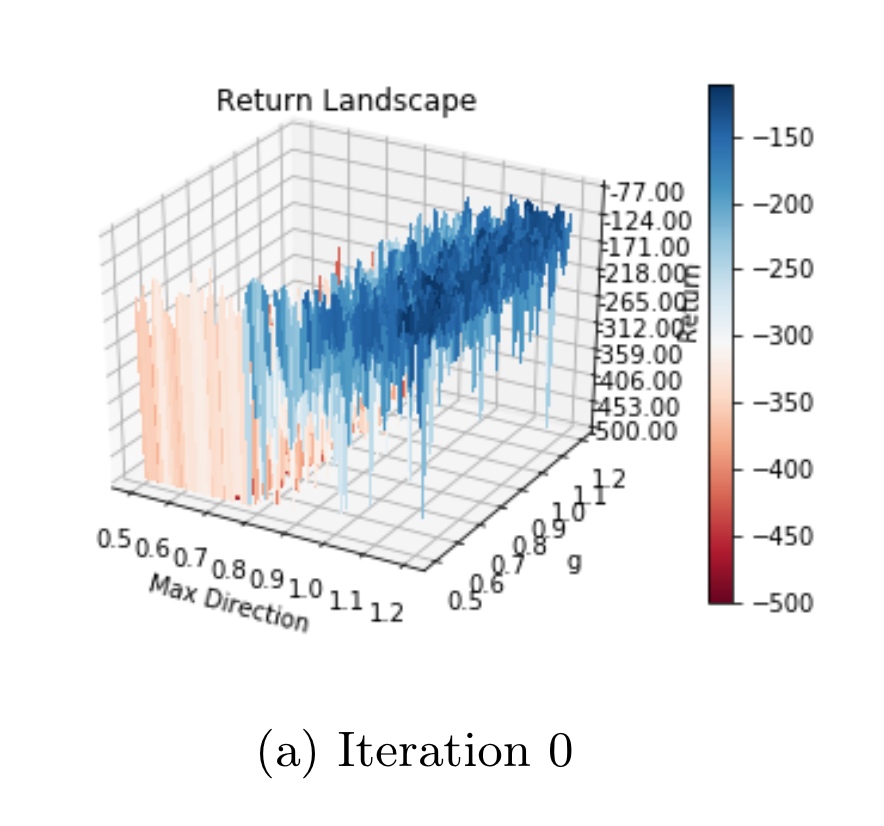
Youssef Diouane*, Aurelien Lucchi*, Vihang Patil* International Conference on Artificial Intelligence and Statistics (AISTATS), 2022 arXiv In this work, we design a novel optimization algorithm with a sufficient decrease mechanism that ensures convergence and that is based only on estimates of the functions. We demonstrate the applicability of this algorithm on two types of experiments: i) a control task for maximizing rewards and ii) maximizing rewards subject to a non-relaxable set of constraints. (*equal contribution) |
|
Michael Widrich, Markus Hofmarcher, Vihang Patil, Angela Bitto-Nemling, Sepp Hochreiter Offline RL Workshop, Neurips, 2021 video We introduce modern Hopfield networks for return decomposition for delayed rewards (Hopfield-RUDDER). We experimentally show that Hopfield-RUDDER is able to outperform LSTM-based RUDDER on various 1D environments with small numbers of episodes. |
|
Vihang Patil 2019 We propose a new convergent hybrid method which utilizes policy gradient directions to search in a smaller sub-space, called Guided Evolution Strategies with Sufficient Increase. |
|
Modified from Jon Barron's website. |